Why voice-first healthcare AI needs medical-grade ASR pipelines
The future of healthcare speaks. And only medical-grade ASR can listen.

Building toward a voice-powered future
Healthcare applications are moving toward a voice-powered future. This vision points to a future where clinicians and patients speak, and intelligent infrastructure handles the rest: capturing data, structuring it, and feeding it into reasoning systems that assist with documentation, coding, and clinical decision support.
- Major EHR platforms are becoming mobile-first and voice-activated, shifting clinicians away from screens and toward ambient, conversational experiences.
- Ambient scribes like Tandem, Heidi, and Nabla are alleviating documentation burden by listening during encounters and generating structured notes in real time.
- Specialized AI assistants like RadAI are are transforming radiology workflows by capturing spoken findings, generating draft reports, and supporting structured documentation directly from voice input.
Medical speech recognition sits at the center of this transformation. It captures the raw language of care, i.e. the words that define diagnoses, treatments, and clinical reasoning, and converts it into the data that powers everything else. The accuracy, structure, and adaptability of this layer determine how effectively voice-driven applications can serve clinicians and patients.
For developers, this evolution introduces exciting opportunities but also new demands. Building reliable, voice-first systems that can really scale in clinical environments requires infrastructure that understands clinical language, adapts to new terms, and produces structured outputs that downstream AI can reason over.
Why a pipeline, not just a model
Most speech recognition solutions fall into one of four groups, each with distinct strengths and trade-offs:
- Walled Gardens – Vertical, end-user-focused products that offer strong medical accuracy and built-in voice commands but limited transparency or customization for developers.
- Swiss Knives – General-purpose, API-first platforms that deliver good latency and competitive pricing but lack clinical depth and domain adaptation.
- Commons – Point solutions with narrow focus, limited flexibility, and minimal support for complex medical workflows.
- Unicorns – Emerging vertical players that combine domain expertise with API access, offering promise but often limited retraining options and ecosystem maturity.
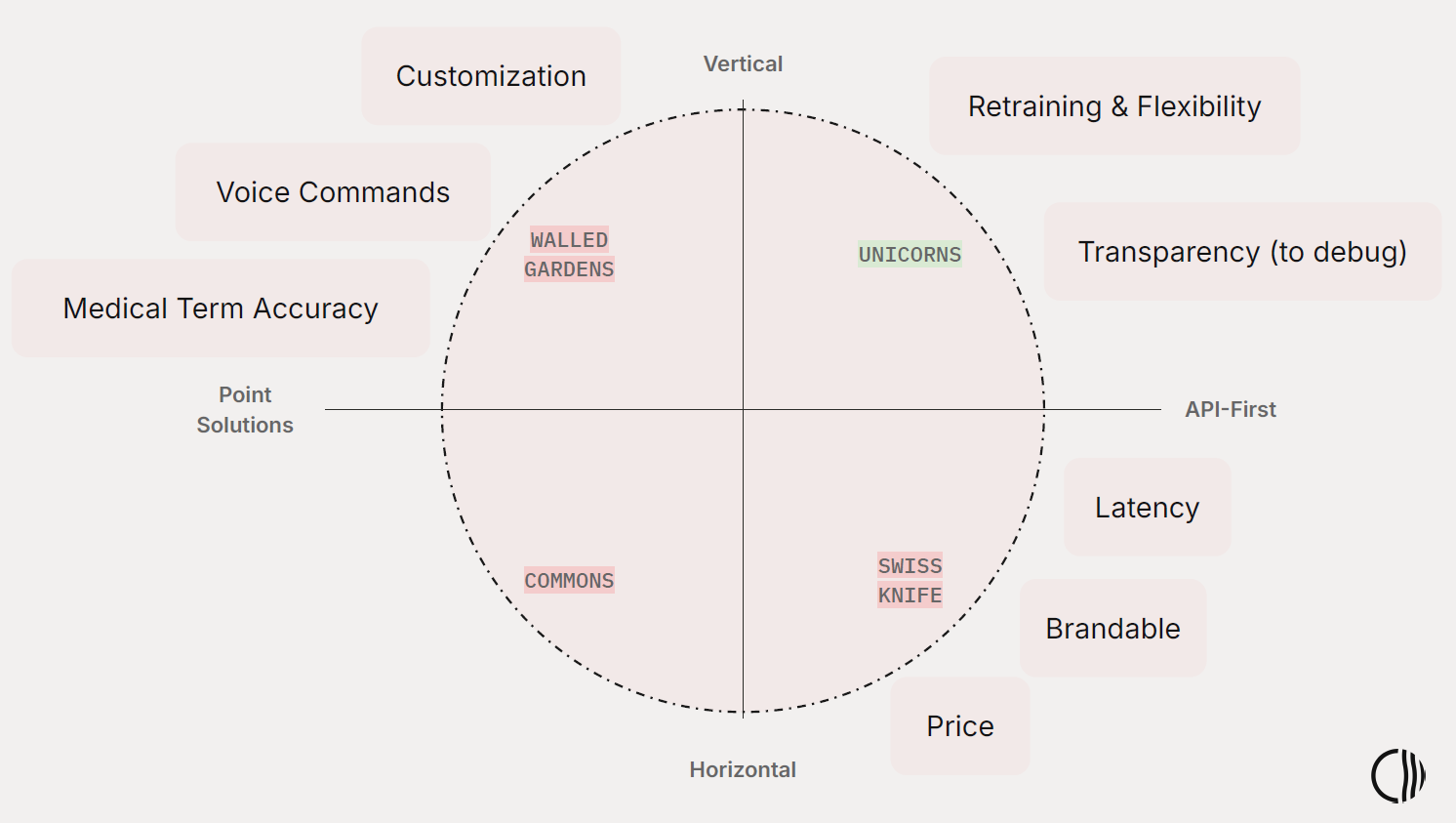
These approaches leave gaps for builders who need both clinical precision and developer control. Some excel in accuracy but are too rigid to extend, while others are flexible but fail to capture the nuance of medical language.
Healthcare language carries structure, semantics, and risk that cannot be handled by a single model or generic pipeline. It requires a medical-grade ASR architecture built to orchestrate multiple components. Acoustic models, domain-specific language layers, formatting modules, and enrichment steps, all seamlessly working together.
That architecture is a medical-grade ASR pipeline. Each layer adds fidelity, context, and structure, producing outputs that are accurate, transparent, and ready to power intelligent agents across clinical workflows.
This approach transforms speech recognition from an opaque process into core infrastructure for the agentic age.
Corti's medical-grade ASR pipeline
Our ASR pipeline is a staged system designed to transform raw audio into structured, clinically fluent text. Each stage is modular, purpose-built, and optimized for a specific task.

- Acoustic Model. Converts raw speech into phonemes and base text, tuned on medical data for high term recall.
- Language Model Refinement. Adjusts word choice, resolves ambiguities, and corrects syntax using domain-specific context.
- Punctuation + Formatting. Restores readability, adding sentence boundaries, numerals, units, and correct casing.
- Domain Adaptation Layer. Expands acronyms, standardizes notation, and aligns structure to medical documentation standards.
- [Optional] Post-Processing + Enrichment. Converts transcripts into structured representations, like JSON, SOAP notes, or input-ready text for downstream AI.
Each layer improves fidelity and usefulness. Developers can interact with or extend the pipeline through APIs, biasing recognition toward specific vocabularies, adjusting formatting, or adding custom post-processors.
The result is an ASR engine that transforms raw speech into structured, clinically aware text ready for downstream systems.
Built for the agentic age
The Agentic Age in healthcare will be defined by autonomous, composable systems. AI can now plan, act, and collaborate across workflows, coordinating reasoning and decision-making in real time. For healthcare, this shift means software must do more than react. It must interpret context, maintain accuracy, and supply structured data that intelligent agents can trust.
These systems rely on language as their interface. Every instruction, observation, and action begins with words. If speech recognition fails to capture meaning precisely or produces unstructured text, the entire reasoning chain breaks. In an agentic ecosystem, upstream reliability determines downstream intelligence.
A robust ASR pipeline provides the foundation for this new class of systems. It delivers the accuracy, structure, and transparency that agents need to reason safely and act confidently.
With it, developers can:
- Integrate transcription directly into reasoning, feeding clinically aware text into LLMs or decision trees without extra cleanup.
- Compose structured workflows, routing enriched outputs to summarization, coding, or RCM agents with minimal post-processing.
- Maintain safety and trust Know that outputs are clinically tuned, auditable, and traceable through every processing stage, reducing the risk of silent errors.
- Adapt continuously, updating vocabularies or biasing terms in real time as medical language evolves.
Agentic systems can only perform as well as the data they receive. A pipeline designed for clinical speech ensures that what they hear, interpret, and act on is complete, contextualized, and ready for autonomous reasoning.
Quick takeaways
- Medical speech recognition requires a pipeline, not just a model. Generic ASR solutions lack the clinical depth and structure needed for healthcare. You need a multi-stage system with acoustic models, language refinement, formatting, and domain adaptation working together.
- Most ASR solutions force you to choose between accuracy and control. Walled gardens offer medical accuracy but no flexibility. General-purpose APIs are flexible but miss clinical nuances. You need both.
- Agentic healthcare systems depend on structured, clinically-aware input. If your ASR produces unstructured or inaccurate text, downstream AI agents (for documentation, coding, decision support) will fail. Upstream reliability determines downstream intelligence.
- Look for pipelines you can extend and compose. The best medical ASR lets you bias vocabularies, adjust formatting, and add custom post-processors through APIs so you can adapt as medical language evolves and integrate directly into your reasoning workflows.
- Bottom line: Voice-first healthcare applications are here. To build reliable, scalable apps, you need ASR infrastructure that understands clinical language, produces structured outputs, and gives you developer control.